
The Era of Multi-Agent Imagined Experience
Why the next leap in machine intelligence won't be learned alone—it will be learned by agents playing, competing, and cooperating inside world models

Ahmet Hamdi Guzel
June 12th, 2026
The Story of Modern AI in Three Acts
In the first act, the era of self-play, agents learned by trial and error inside closed worlds with a single, crisp objective. This is the era that gave us superhuman play in backgammon, Go, chess, and Atari—agents that discovered strategies no human had taught them.
In the second act, the era of imitation, the field pivoted to imitation: train on the vast corpus of everything people have written and said, and a single model inherits a startling breadth of competence. This is the era of the large language model.
David Silver and Richard Sutton have argued, persuasively, that we are now entering a third act: the era of experience. Imitation can reproduce what people already know, but it struggles to exceed it. To go further, agents need to generate their own data—to act, observe the consequences, and improve from grounded signals in their environment rather than from human pre-judgment. The ceiling stops being human knowledge and starts being the agent's own capacity to explore.
We find this framing compelling, and we'd add one thing to it. The richest streams of experience come from sharing a world with others—teammates to coordinate with, rivals to outwit, partners whose behavior you have to predict. The era of experience is, almost by definition, a multi-agent era. This is the conviction behind much of our recent work.
And multi-agent worlds have a property no single-agent world can: they never run out of problems. Each time one agent improves, it becomes a harder problem for the others, so the challenges keep escalating on their own. The further idea we'll build is that a world model can generate those challenges directly, rather than wait for us to design them. That open-endedness is the thread we want to pull on here.
What a Single Mind Can Learn in a Dream
The most important idea in this story is deceptively simple: an agent doesn't have to learn in the real world. It can learn inside a world model—a learned simulator of its environment—and then carry that skill back out.
The clearest demonstration of this is the Dreamer line of work. The original Dreamer learned behaviors entirely "in imagination," training a policy by rolling forward a learned latent model of the world rather than the world itself. Successive versions kept widening the aperture: DreamerV2 reached human-level on the full Atari suite from a single GPU, and DreamerV3 mastered 150-plus tasks across 2D and 3D worlds with one fixed recipe—famously becoming the first system to collect diamonds in Minecraft from scratch, with no human demonstrations. The latest, Dreamer 4, learns a fast, playable world model from offline video and trains agents inside it, obtaining diamonds without ever touching the real game during training.
Others have shown the same lesson with different machinery. IRIS framed the world model as a sequence problem—tokenize the screen, predict the next token, exactly as a language model does—and matched human performance on Atari from the equivalent of two hours of play. DIAMOND used a diffusion model so that fine visual detail survives the compression, and showed the same approach could simulate a 3D shooter, not just Atari. Imagined Autocurricula went further still: the agent doesn't just learn inside the world model, it builds its own curriculum within it—starting from short "dreams" and progressively scheduling longer, harder ones—and generalizes to brand-new levels it has never seen, learned purely from offline data with zero interaction with the real environment. And agents like SIMA have begun following language instructions across many commercial 3D games at once, even improving by generating their own goals.
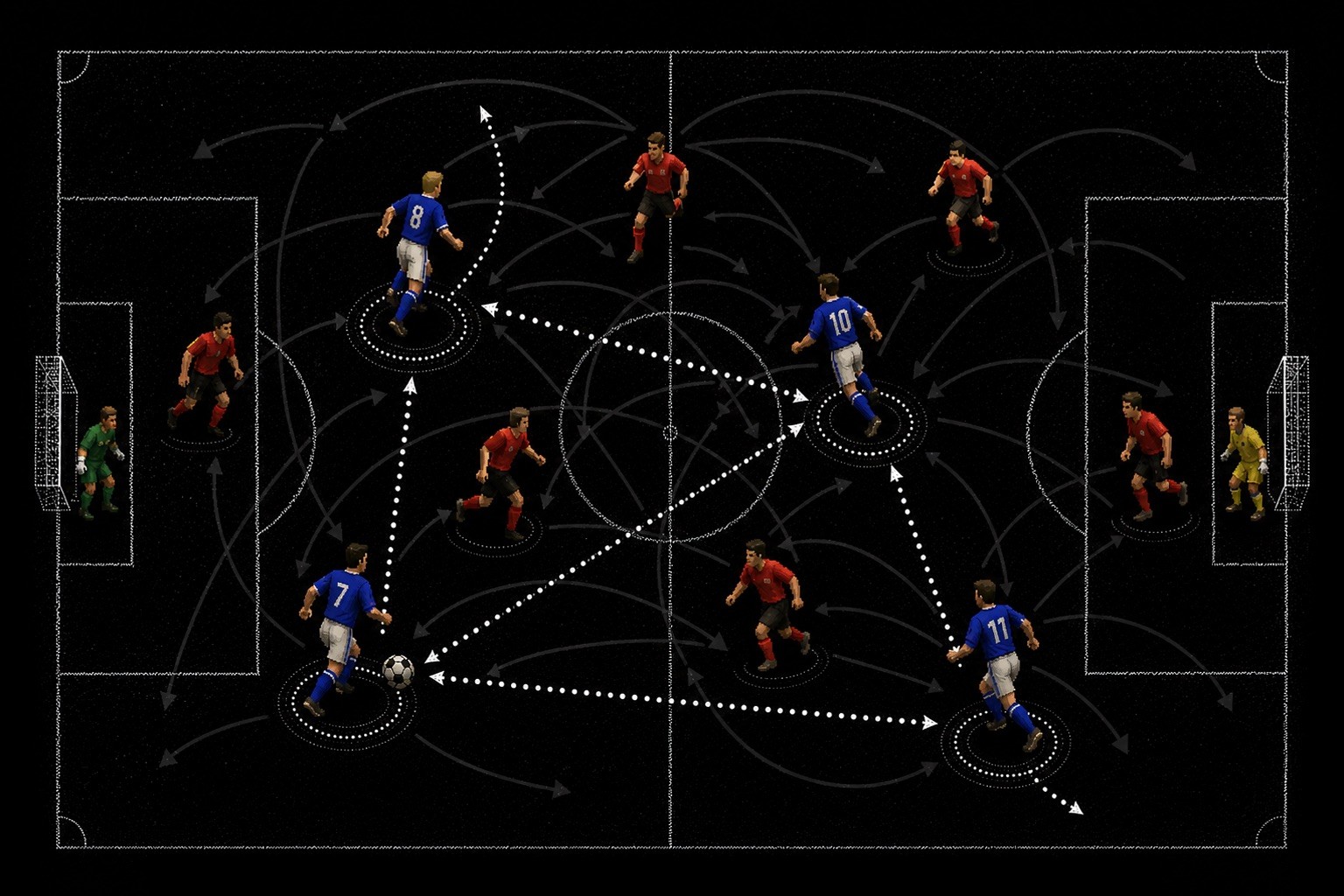
Agora-1, our multi-agent world model, opens that world to many participants at once, human or AI, inside the same generated simulation. And PROWL keeps it honest, stress-testing that simulation with adversarial agents. Why those two matters will take the rest of this story to tell—and it starts with a detour through the games where reinforcement learning first learned to win.
A shared deathmatch simulation, powered by Agora-1
When Reinforcement Learning Learned to Win
Games have always been a critical proving ground for AI, and the high-water marks are worth remembering. In StarCraft II, a reinforcement learning agent reached Grandmaster rank, above 99.8% of ranked human players, in a game of hidden information and long-horizon strategy. In Dota 2, a team of five coordinated agents beat the reigning world champions—the first AI to win an esport at the highest level.
What's easy to miss is how these systems got there. They didn't just learn against a fixed opponent. They learned against self-play, and against a growing population of past and present versions of themselves. The StarCraft agent trained inside a "league" of continually adapting strategies and counter-strategies; the Dota agents played the equivalent of many decades of games against themselves every day. Each improvement in one agent became a harder problem for the others. The curriculum wasn't designed—it emerged from competition.That detail is the bridge to everything that follows.
Why One Agent Is Not Enough
Self-play gave those systems their curriculum, but it did so inside the real game engine. Here is the problem with moving it into a world model. A world model that assumes a single actor quietly assumes the rest of the world holds still. The moment you add other learning agents, that assumption breaks: as your teammates and opponents change their behavior, the dynamics of the world itself change underneath you. What looked like a fixed environment becomes a moving target. This is the central difficulty of multi-agent learning, and it's why a single-agent world model, however good, can't simply be pointed at a team game and left to run.
The research community has been circling this for years. Cooperative benchmarks like the StarCraft Multi-Agent Challenge (and its procedurally-generated successor, SMACv2) made the coordination problem concrete and measurable, and value-decomposition methods like QMIX gave teams a way to learn together while still acting independently. More recently, a cluster of work has begun extending world models themselves into the multi-agent setting—MAMBA showed agents could learn cooperative tasks largely inside imagination; MARIE and CoDreamer brought transformer- and Dreamer-style world models to teams of agents; MATWM added the ability to anticipate what teammates will do under partial information.
Almost all of this work is cooperative, and almost none of it is built around competitive self-play. That gap is exactly where we've been investing. Our multi-agent world model is, in effect, a learned competitive and cooperative arena: policies can be trained entirely inside it, against and alongside other agents, and may then generalize to opponents and environments they've never seen.
Open-Endedness: The Engine That Never Stops
The reason this matters goes beyond efficiency. Multi-agent worlds are the most reliable source we know of for open-ended learning—the property that a system keeps generating new problems for itself indefinitely.
The intuition is vivid in hide-and-seek: from nothing but a simple game and two competing teams, agents progressed through escalating phases—building forts, then using ramps to breach them, then locking the ramps away, then exploiting the physics in ways the researchers never anticipated. No one designed those strategies. Each one was manufactured by the opposing team's attempt to win. The same principle, scaled up, produced generally capable agents trained across a vast, procedurally-generated universe of multiplayer games, and it traces back to ideas like POET, where environments and the agents that solve them co-evolve forever.
We think this is the deepest reason to care about multi-agent world models, and it connects directly to our own PROWL work, where an adversarial agent actively hunts for the world model's failures and turns them into new training data. Passive demonstrations cover a vanishingly small slice of what can happen when many agents interact—the collisions, the contested objectives, the improvised coordination. Open-ended interaction generates that missing experience. Over time, agents and world models can push one another into ever-harder regimes, each closing the other's gaps. That is the era of experience, made concrete: a stream that never runs dry because the agents themselves keep extending it.
Worlds That Design Their Own Challenges
Today, the way you measure a multi-agent team is against challenges someone built by hand. Cooperative StarCraft micromanagement—the SMAC benchmark and its successor SMACv2—is where research labs and universities currently compete, and it's a serious bar to clear. But it's also a fixed one. SMACv2 had to be built at all because agents learned to memorize the original scenarios rather than truly generalize. Hand-curated challenges, however good, eventually run out.
So here is the direction that excites us most: what if the team's challenges weren't curated by us at all, but generated by the world model itself?
This is the idea behind unsupervised environment design: train an adversary to propose the situations where the learner struggles most, so the curriculum is always pitched right at the edge of the team's ability. Classically, that adversary tunes the knobs of a procedural generator: wider maps, faster units, trickier terrain. Imagined Autocurricula took the next step for a single agent, running that curriculum inside a learned world model rather than a hand-built one. The frontier we want to push is the multi-agent version—and it is a bigger leap than it sounds, because of what a "challenge" even is once a team is involved.
For a single agent, a challenge is the environment: the map, the obstacles, the lone opponent. But on a team, the hardest part of any situation isn't the terrain—it's the other agents. The opponents probing your formation, the teammate who breaks left when you expected right, the coordinated push you've never seen. The most valuable challenges are not only spatial, but also social, and that is exactly what a world model can generate and a procedural generator cannot. Because the model has learned how agents behave, not just how the world looks, an adversary can ask it for difficult teams—opponent strategies tuned to your blind spots, configurations engineered to crack your coordination, situations built around the precise gap between what your team can do and what it can't do yet. These scenarios live in the space of behavior, and only a model that has learned behavior can synthesize them.
Put a team on one side and this generator—the next generation of PROWL, hunting for strategic failures rather than visual ones—on the other, and you get a game with no fixed finish line. The generator searches for the team's weaknesses; the team learns to cover them; the generator searches again. No human writes the curriculum, and no fixed challenge set caps how far it can go. It is, we think, one of the most direct routes to agents that coordinate beyond anything we could have taught them—a team that never stops improving because the world it lives in never stops challenging it.
Toward a World-Class AI Team
So where does this lead?
The single-agent milestones gave us superhuman individuals. The competitive milestones gave us superhuman rivals. What hasn't been built yet—what we think is the natural next landmark—is a world-class AI team: a group of agents that coordinate as fluidly as a championship roster, anticipating each other, covering for each other, inventing plays no playbook contains, and doing it all having learned inside a world model rather than against hand-built game logic. The Dota five were a glimpse of this—but they mastered one fixed game, inside the real engine, at staggering simulated cost. The team we're developing learns its coordination in a world that can keep changing underneath it.

There are early hints that this is possible. Years ago, teams of agents reached human-level in Capture the Flag, a 3D multiplayer first-person game, learning from nothing but raw pixels and the score—and cooperating fluidly with teammates they had never met, human ones included. Nobody scripted that teamwork; it emerged from agents competing and cooperating at scale. (The population-based, multi-agent training that made it work later became part of the foundation for the StarCraft result above.) Teams of simulated humanoids have since learned to play football end-to-end—from individual motor control all the way up to coordinated, off-the-ball team play—purely through multi-agent learning, with behavior that holds up under real sports analytics. Coordination, it turns out, is not something you have to script. Like the strategies in hide-and-seek, it emerges when capable agents share a world and a goal.
Our aspiration is to create an emergent, world-class collaborative team, trained and stress-tested inside a learned simulator that we can shape, reset, and scale at will. The reason to build it reaches well beyond games. Almost every environment where we will want capable agents is a multi-agent one: warehouse robots weaving around one another, drone swarms threading a payload through terrain no single machine could cross, heterogeneous search-and-rescue teams at sea—a spotter, a wincher, a floater—coordinating under conditions that punish hesitation. Reading a teammate's intention, anticipating a rival, covering for a partner: this is the raw material of social intelligence, and games are simply where it can be learned fastest. In the real world, that experience is exactly the data you cannot safely or cheaply collect—you don't get a thousand failed rescues to practice on. A world model is the one place it can be generated at scale, hardened against adversaries, and only then carried out of the dream and into the world. We believe it is now possible to build a team that wins not by individual brilliance but by playing together better than anyone thought machines could—and that it will be built on world models.
Build It With Us
Maintaining a coherent shared world across many agents, keeping it consistent when players lose sight of one another, training stably against a moving population of opponents, and preserving open-ended behavior as the system scales—these are hard, unsolved problems, and they're the ones we wake up thinking about.
If learning intelligence inside shared, open-ended simulated worlds resonates with you, we'd love to talk. The hardest problems are still open—and the most interesting experience is the kind we generate together.



